|
The following fully specifies the format of files LiPG converts into a c++ parser. Each block has a name in italics (in the upper left corner if possible).
|
LiPG Documentation
|
The Lithium
Parser Generator is (obviously) a
parser generator
and is designed to be simple and easy to use. Like lithium, LiPG
(pronounced "lie-pee-jee") can be easily molded into the shape
(or parser) you need. Like most parser generators, LiPG is for creating languages including domain specific languages. In general, LiPG can take pieces of a string input and do actions based on which pieces it finds. Download just the Windows binary here:
LiPGv1.0 (windows).exe
Contents: Using LiPG |
|
Simply put, a
parser generator
is a program that makes it easy to create a
parser. What this means
is that, in essence, the parser generator is a compiler for a domain
specific programming language geared toward creating parsers. One writes a
parser in this special code, then "compiles" it using the parser
generator. The output of the parser generator is generally code in a more
general programming language. The main function of the parser generator's
input language is to make it very easy for you to create complex parsers. |
|
LiPG takes a filename
either as a single command-line argument, or (if you don't input a
command-line argument) it will take a filename from standard keyboard
input. On windows, you can simply drag a file formatted for LiPG onto the
executable. |
|
|
The code for each tutorial should be in the LiPG v1.0.zip file. If you don't want to download that, a link to the tutorial source code is at the bottom of each tutorial. |
glob
#include <stdio.h>
tutorial0(&diff, exampleInput, strlen(exampleInput));
parse tutorial0
-> "hello"
[ printf("H E L L
O");
else
|
glob
parse phoneNumber
top
-> ( a b c ) a[ '0' <= a&&a <='9'
]
[ tempString1[0]=a;
-> ( " " a b c )
a[ '0' <= a&&a <='9' ]
|
glob
parse phoneNumber
-> ( X " " Y "-" Z ) X[ '0' <= X[n]&&X[n]
<='9' && n<3 ]
cond[ strlen(X)==3 && strlen(Y)==3
|
glob
parse phoneNumber
parse num
|
Tutorial 4 - Simple Integer Calculator
glob
parse
SICalc
parse expression
every ws[] [
// do nothing ]
more->
("+" product[&temp])
]>more
else
parse product
(integer[&temp1] "*" product[&temp2])
parse integer
parse ws
|
glob
onfail
onmismatch
tween " "
-> else
"a" cond[ globalVar==4 ]
-> noevery
notween
"" cond[ globalVar==4 ]
|
LiPG file format - Full specification
|
The following fully specifies the format of files LiPG converts into a c++ parser. Each block has a name in italics (in the upper left corner if possible).
|
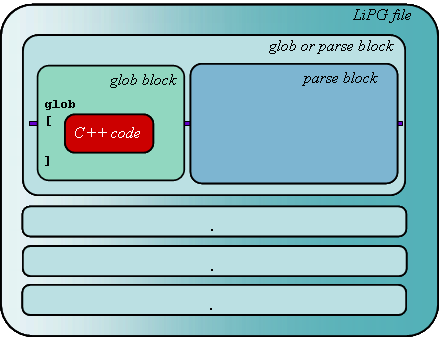 |
The LiPG
file block represents the
whole LiPG file. LiPG files consist of a set of parse blocks and
glob blocks ("glob" stands for "global"). glob blocks
just wrap C++ code (including 'main') and drop the code in the output file wherever they are
written in the input file relative to other glob blocks and
parse blocks. |
 |
Parse blocks are the important parts of an LiPG file. They represent
a function that can be called in C++ code or other parse functions. |

|
anychar,
anychar[ ], and anyindex declarations look exactly like normal
C-declarations, except they do not end in a semi-colon. |
|
|
A parse function call
consists of the name of the function and regular C++ arguments
inside brackets. In addition to normal C++ variables, anychar and
anychar[ ] variables can be passed as well (as their underlying
data-type is a simple char* variable). |
 |
|
The wordform is essentially the pattern to match for a given choice. That pattern can either be a single quote, word, or parse function or can be a multiform which is a list of any of those enclosed in parentheses and separated by white-space. A quote is any C-style double quoted string. A variable can be a normal C-string variable, or can be an anychar or anychar[ ] variable. A parse function call is a powerful way of reusing parse functions.. |
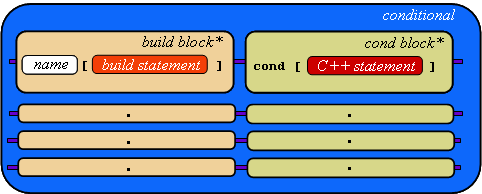 |
|
The conditional
puts constraints on anychar and anychar[ ] variables.
|
Calling a parse function as a C++ function
|
name(diff, input, length, parse_arguments) |
To call a parse
function from C, it requires some arguments that are implicit parameters
in the definition of the function. Here, the 'name' is the name of the
parse function, 'diff' is an int* variable that will contain the number of
characters parsed, 'input' is a char* variable and is the string to be
parsed, 'length' is the length of 'input'. |
Copyright 2008, Billy Tetrud
BillyAtLima@![]()


